Matrix Algebra Problems with Applications in Psychology and
Multivariate Analysis
Multivariate Data Analysis
Michael Friendly
York University
Psychology 6140
Students in Multivariate Analysis need to develop skills in working
with matrices and reading matrix expressions. Some of the skills
which seem to be important are:
- Performing simple matrix calculations
- Manipulating algebraic expressions in matrices-substituting
identities, simplifying expressions, etc.
- Formulating substantive and statistical problems in matrix
terms-or, recognizing such in journal articles.
- Understanding certain key results (theorems) of matrix algebra.
- Recognizing these results when they are used in your text.
The following problems are directed toward developing these skills.
Along the way, some matrix applications in psychology and multivariate
statistics are introduced.
I. Elementary matrix expressions
-
Factoring a matrix into the product of two matrices is the
basis of many methods in multivariate analysis. Choleski's
method involves factoring a matrix into the product of two
triangular matrices, one of which has 0s above the
diagonal, the other below the diagonal.
Fill in the ?
| Hint: Let each ? be an unknown letter; solve the equations. |
entries in the following matrix equations:
-
|
|
é
ę
ë
|
|
ů
ú
ű
|
= |
é
ę
ë
|
|
|
ů
ú
ű
|
× |
é
ę
ë
|
|
|
ů
ú
ű
|
|
|
-
|
|
é
ę
ę
ę
ë
|
|
ů
ú
ú
ú
ű
|
= |
é
ę
ę
ę
ë
|
|
|
|
ů
ú
ú
ú
ű
|
× |
é
ę
ę
ę
ë
|
|
|
ů
ú
ú
ú
ű
|
|
|
-
Premultiply the matrix M by each of the following
matrices. Describe in words in each case what effect the
premultiplier has on the rows of M.
|
A = |
é
ę
ę
ę
ë
|
|
ů
ú
ú
ú
ű
|
B = |
é
ę
ę
ę
ë
|
|
ů
ú
ú
ú
ű
|
C = |
é
ę
ę
ę
ë
|
|
ů
ú
ú
ú
ű
|
|
|
-
Let D be an m ×n matrix and let ei = ( 0, 0, Ľ, 1, 0, Ľ, 0 )˘
denote the n-dimensional vector consisting of zeros except
for the i-th element, which is 1.
- What is D ei (in words)?
- Express the matrices A and B from
Problem 12
above in terms of e vectors.
-
Experimenters in color vision have found that a subject can
match any spot of colored light by an additive mixture of
three colored lights of fixed spectral composition (Judd,
1951). Any three colors can be used as the primary lights
provided that none is a combination of the other two.
Say that an experimenter has a colorimeter that has three
primary lights with values r, g, and b. She
wants to specify her results in terms of a standard set of
tri-stimulus values, R, G, and B. By
experiment she finds that the amount of each of the standard
primaries needed to match each of his primaries is
Define the appropriate vectors and matrices to express the
above system of equations in matrix terms.
-
Let
x = (x1,Ľ,xn)˘
be a
vector containing the number of units purchased of each of a
variety of grocery items. Let
y = (y1,Ľ,yn)˘
be a vector of unit prices, such that
yi = the price/unit of item i. For example,
x = ( 4 , 3 , 2 ) ˘ and y = (.95 , .25 , 6.50 ) ˘ might represent 4 dozen eggs at
$0.95 per dozen, 3 lbs. of apples at $0.25/lb, and 2 cans of
pate de fois gras at $6.50 per can (cheap, if it's entier).
- Formulate a matrix expresstion for the total (net) cost
of the commodities in x.
- Suppose each commoditiy is subject to a particular rate
of tax, these being given by a vector,
t = t1,Ľ,tn˘
so that if
commodity i is taxed at 5%, ti = 0.05.
Formulate an expression in terms of matrices and
vectors for the total cost of x including
taxes. [Remember, cost after tax = net cost × ( 1 + t).]
-
Cliff (1959) showed that the affective value of an
adverb-adjective combination (e.g., moderately nice)
could be predicted quite accurately by multiplying an
affective value for the adjective (nice) by an intensity
value for the adverb (moderately).
Suppose one took a set of m personality-trait adjectives
like industrious, happy, carefree, shy, etc. and formed
all possible combinations of these with n adverbs,
seldom, somewhat, moderately, extremely-m ×n pairs.
If a group of
people rated each combination on an evaluative scale, the
average ratings could be assembled in an m ×n
matrix, C = { cij } = average rating of
adverb i and adjective j. Let v = (v1,Ľ,vm )˘
be a vector of
intensity values for the adverbs and d = (d1,Ľ,dn)˘
be a vector of average
ratings for the adjectives by themselves. Cliff's model was:
where k is a constant. [Cliff's model fit the data
rather well, in fact, and created considerable interest in the
possibility of developing mathematical models of aspects of
language.]
- Express C in this model as a product of two
matrices.
| Hint: The number of summed terms is the number of columns in
a matrix product. |
- If this model holds, what is the rank of C?
-
A quadratic function of a scalar variable, x can be
written
|
f ( x ) = b0 + b1 x + b2 x2 |
|
- Express f ( x ) as an algebraic expression of the
vectors b = ( b0 , b1 , b2 ) ˘
and x = ( 1 , x , x2 ) ˘.
- In terms of this expression, evaluate f ( 2 ) for
b = ( b0 , b1 , b2 ) ˘.
- Generalize to find an expression for an n-th degree
polynomial of x,
|
f ( x ) = b0 + b1 x + b2 x2+ Ľ+ bn xn |
|
- If person i has a value of xi, let xi
be the vector ( 1 , xi , xi2 ) ˘.
Write a matrix expression which will give the values of
f ( xi ) as a vector for all persons in a group.
[Completing this question, you have just (re-)discovered the
General Linear Model!]
-
Let jn be a column vector of n unities
(ones). Using the following vectors,
find each of the following inner products with j3.
State in words the effect of taking an inner product with
jn.
- a˘ j3
- b˘ j3
- j˘3 c
- x˘ j3
[Matrix notation was invented to simplify the expression of linear
equations. The operation of multiplying vectors by the unit
vector has a particularly simple interpretation.]
-
Let X be a N ×p matrix consisting of the
scores of N people on p tests, where xij =
the score of person i on test j. Define the
matrix Z ( N ×p ) of standard scores,
zij = ( xij - [`x]j ) / sj. From
the fact that the correlation between two standardized
variables is rij = ( [1/N] ) ĺi = 1N zji zik, show that the p ×p matrix of all
intercorrelations can be expressed as
[In standard scores, the correlation is simply the average cross-product.
Isn't that nice?]
II. Applications: Choice, preference and graph theory
The problems in this section deal with applications of matrix algebra
to representing relationships among objects by matrices and directed
or undirected graphs. Two basic type of relations between objects
can be represented in this way: An incidence matrix
contains entries of 0 or 1 in cell i, j to indicate that the
object in row i is related in a symmetric way to the object in
column j. A dominance or preference
matrix also uses binary entries, but the relation is not necessarily
symmetric, as in ``person i likes person j'', or ``player i beats
player j'' in a tournament.
-
In a sociometric experiment, members of a group are asked which
other members they like. Suppose the data are collected in a
choice diagram as given in Figure 1,
where an arrow going from i to j means that ``i likes j''.
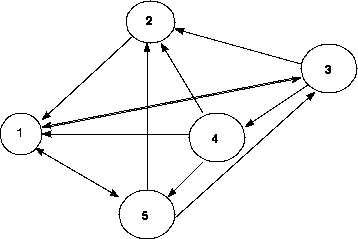 Figure 1:
Directed graph for a sociometric
experiment. A directed arrow points from a person to the person
he/she likes.
Figure 1:
Directed graph for a sociometric
experiment. A directed arrow points from a person to the person
he/she likes.
- Convert the diagram to a matrix, C, where cij = 1 if i likes j, and 0 otherwise. The
diagonal elements, cii = 0.
- Let u be an n ×1 vector with unit
elements. One might say that u ˘ C gives
scores for ``popularity''. Explain why.
- Explain how C u can be interpreted as
scores for ``generosity''.
-
Suppose B is a similar matrix of choices, where
Imagine a similar matrix, P , where pij = 1 if
j believes that i likes him and pij = - 1 if j believes that i dislikes him. The
diagonal elements of B and P are equal to 0.
- Let N = P ˘ B, so that
nij = ĺpki bkj. Explain why nij
can be interpreted as a measure of ``identification''
between person i and person j.
- Determine whether the diagonal elements of N can
be interpreted as a measure of ``realism'' (k is
realistic if his beliefs about who likes him agree with
reality).
- Determine whether the diagonal elements of B P˘ can be interpreted as a measure of
``overtness'' (k is overt if his beliefs about X
conform to X's likes and dislikes).
- Compute the matrix C2 = C ×C
and interpret the elements of this matrix.
- Try also to find an interpretation for the elements of
C3.
- Is there any interpretation you can come up with for the
elements of
C C ˘ or C ˘ C?
-
The expression, u ˘ C, where u is
a unit vector, tells how often a person is liked, so it is a
measure of popularity. Suppose two persons are chosen equally
often, but the first is liked by popular people and the second
is liked by less popular people; then it may be reasonable to
say that the first person is more popular, since he/she has
more indirect choices.
Suppose now we want to combine direct and indirect choices in
a measure of popularity, defined as follows: Define a
``transmission'' parameter, 0 < p < 1, and assume that
each direct choice contributes an amount p to a person's
popularity; an indirect choice through one intermediate person
contributes an amount p2; an indirect choice through two
intermediates contributes an amount p3, etc.
- Show that the measure that takes into account all
indirect choices in this way can be found from the
vector u ˘T, where
|
T = p C +p2 C2 +p3 C3 + Ľ+p n-1 C n-1 |
| (1) |
- Show that the following identity holds for T
defined above:
This equation provides a way to solve for T
without evaluating the entire matrix sum in equation
(1).
| Hint: Form a second equation by multiplying (1) by C, and subtract. |
- Show that equation (2) above is equivalent to
where, t ˘ = u˘T
and s ˘ = u˘C.
[Source: Van de Geer (1971)]
-
Consider a hypothetical sociometric choice matrix for three
people, as in the previous problem:
and assume that the quantity p, the relative
effectiveness of transmission thru a sociometric link, has the
value 1/2. Solve for the respective elements of t,
the vector of status indices.
-
In a paired comparison experiment, a subject is presented with
all pairs of stimuli that can be formed out of a set (e.g.,
political candidates), and is asked to indicate for each pair
which stimulus he prefers. For n stimuli, the data can
be collected in square matrix, X of order n × n where xij = 1 if j is preferred to
i and is 0 otherwise. The diagonal elements are zero.
- Verify that if xij = 1 then xji = 0 where i ą j.
- Figure 2 gives a diagram of choices, where an arrow
going from i to j indicates that i is
preferred to j. Convert this diagram to a choice
matrix X.
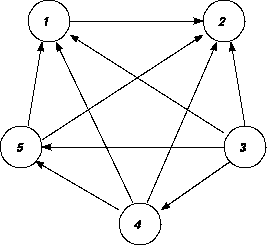 Figure 2:
Choice graph for a paired comparison
experiment.
Figure 2:
Choice graph for a paired comparison
experiment.
- Calculate u˘ X where u is
a unit vector and interpret the elements of the
resulting vector.
- Rearrange the rows and columns of X in such a way
that all 1 elements are above the diagonal, so the
result is a triangular matrix. Interpret the order of
the rows and columns in this new matrix.
- Inspection of the diagram reveals that all choices are
transitive, that is for any three stimuli, if
i is preferred to j and j to k,
then i is always preferred to k. If
k were preferred to i, we would have a
circular triad. Draw a diagram in which circular
triads do occur, and convert it to the corresponding
choice matrix. Calculate u ˘ X for
this matrix, and compare the value for the result for
a transitive matrix.
- Let v = u ˘ X. Compare the
values of v ˘ v as calculated
from the figure with those calculated from the matrix
X you constructed in part (e). What effect does
the presence of circular triads have on the values of
v = u ˘ X?
-
The problem in archeology of placing sites and artifacts in
proper chronological order is called sequence dating or
seriation. The same problem, of ``putting in order''
arises in developmental psychology and test theory, but the
context in archeology is simplest.
An assumption made in archeology is that graves which are
``close together'' in temporal order will be more likely to
have similar contents than graves further apart in time.
Consider the situation in which various types of pottery,
P1 , P2 , ... Pn are contained in graves G1 , G2 , ... Gm. Let A be the m ×n
matrix with elements,
- Show that the element gij of the matrix G = A A ˘ is equal to the number of common
varieties of pottery found in both graves Gi
and Gj.
- Show that the diagonal element, gii of G
gives the number of varieties of pottery in grave
Gi
- Show that the archeological assumption stated above is
equivalent to the statement that the larger the
gij, the closer the graves Gi and Gj are
in time.
- If five types of pottery are contained in four graves
according to the matrix A below, find G,
and arrange the four graves in time order.
[Source: Williams (198?), Kendall (1969)]
-
In a Markov model for short term serial recall, Murdock (1976)
suggests that an item (e.g., nonsense syllables, like DAXUR)
may be in any one of three states for a learner:
- state IO
- where both item and order information have
been retained (i.e., the learner remembers the
elements of the item and the order in which they
occurred).
- state I
- where only item information is retained (i.e.,
s/he remembers it contained D, A, X, U, R but not
what order they were in).
- state N
- where neither type of information is retained.
A Markov model is specified by identifying the states
and by specifying a ``transition matrix'', which contains the
probabilities that the item changes from one state to another.
In Murdock's model, the transition probabilities are shown
symbolically in the matrix T below.
The parameters are defined as follows:
- a gives the probability that an item will leave
the state IO.
- If it leaves that state, b is the probability that
item information as well as order information will be
forgotten.
- Given that the item is in state I (order information has
not been retained), c is the probability that
item information will be forgotten as well.
A characteristic of the Markov model is that these
probabilities apply to each interval of time, Dt
during the retention interval. Murdock further assumes that
at the start of the retention interval, an item starts in
state IO with probability p, and with probability 1 - p
it starts in state I. The psychological rational
here might be that encoding an item at all establishes item
information, and something more is required for the learner to
encode serial order too. An attentive subject would never
miss an item completely (Murdock assumes), so there is no
probability that an item starts in state N. These starting
state probabilities can be put in a vector, s,
- Show that the probabilities that an item is in any of
the states, IO, I, or N after 1 time interval, D t is s ˘ T.
- Show that after 2 transition intervals, the
probabilities are s ˘ T ×T = s ˘ T2, and after 2 time intervals,
they are s˘ T3. [You may reason
from the result of part (a), together with the diagram
above, rather than multiplying the symbolic matrix
entries.]
- Assume parameter values of p = 1.0, a = b = 0.1, and c = 0.5. Find the probabilities that
an item is in state IO, I, and N after 1, 2, and 3
transitions.
-
The matrix M below represents the performance of five
people on three binary items, where mij = 1 indicates
that item i is answered correctly by person j.
- Calculate the product M M˘. What do
the diagonal elements represent? What do the
off-diagonal elements represent?
- Calculate the product M˘ M. What do
the diagonal elements represent? What do the
off-diagonal elements represent?
-
In studies of perceptual identification, it is common to
present stimuli (say, letters) in a background of noise and
require the subject to identify the stimulus seen or heard.
For n stimuli, the results are collected in an n ×n matrix, X, where
|
xij = Prob ( subject says j | stimulus i was presented ) |
|
In studying the relationships between stimuli in such a
matrix, it is sometimes assumed that confusions are symmetric,
xij = xji, but for some types of stimuli, the results
are not symmetric.
- Express the average proportion of correct responses as a
function of the elements of X.
- Show that an arbitrary square matrix, X can be
expressed as the sum of two matrices,
where S = ( X + X ˘) / 2 is
symmetric, and A is a skew-symmetric
matrix, i.e., aij = - aji.
- Why might it be reasonable to regard A as
containing ``pure asymmetry'' information and S
as containing ``pure symmetry'' information?
[Psychological models for perceptual identification sometimes
assume symmetry for errors, and sometimes do not. The decomposition
of X allows both to be studied.]
III. Bases, orthogonality and vector spaces
-
On a sheet of graph paper,
- Draw directed lines from the origin to represent the
vectors,
- Draw on the graph directed lines which represent the
vectors:
- The vectors a and b form a basis
for the two-dimensional vector space of the graph
paper. Show that each of p, q,
r, s, and t can be
expressed as linear combinations of a, and
b of the form,
where n and m are real numbers.
- The vectors p and q also form a
basis for this vector space. Show that a,
and b can be expressed as linear
combinations of p, and q of the
form, u p + v q where
u and v are real numbers.
-
Show that the vector c = ( c1 , c2 , ... cn ) ˘ is orthogonal to the vector
( 1 , 1 , Ľ 1 ) ¸Ön if and only if ĺ i = 1 n ci = 0.
-
Consider the set of (n - 1) n-dimensional vectors:
|
|
|
|
( 1, -1, 0, 0, ..., 0 ) ¸Ö2 |
| |
|
|
( 1, 1, -2, 0, ..., 0 ) ¸Ö6 |
| |
|
|
( 1, 1, 1, -3, 0, ..., 0 ) ¸Ö12 |
| |
|
| |
|
| ( 1, 1, 1, 1, ..., 1, -(n-1) ) ¸ |
| ______
Ö n2 - n
|
|
|
|
These vectors are referred to as Helmert contrasts
. They are useful for comparing ANOVA factors whose levels
are ordered, but not quantitative. Show that for n = 5
the vectors, c1 , c2 , ...,
c n - 1 :
- are all orthonormal (i.e., pairwise orthogonal and of
unit length).
- are all orthogonal to the unit vector, jn.
- any other vector d, which is orthogonal to
the unit vector, jn. can be expressed as a
linear combination of c1, c2,
..., c n - 1 .
These three facts imply together that any other set of
contrasts among n levels can be expressed in terms of c1,
c2, ..., c n - 1 . Isn't that nice?
-
Consider the n ×n matrix
- Show that rank( C ) = n - 1.
- Show that C j = 0. That is,
j is orthogonal to every row of C, so
C is the orthogonal complement of j.
- Let x· = ( x ·1 , x ·2 , ..., x · n ) ˘ be the means of n treatment groups in a
single factor experiment. Interpret
x·˘ j .
- Evaluate C x·. Using the
results of (a), (b), and (c) above, show that C x· is a vector of n
contrasts among the group means, of which only n - 1
are independent. What do these contrasts
represent?
-
If c1 , c2 , ..., cn
are vectors, all orthogonal to a vector x, show
that any vector in the span of c1 , c2 , ..., cn is orthogonal to x.
-
Show that any linear combination of a set of independent
contrasts is also a contrast.
-
Given the three 4-dimensional vectors below, suppose we wish to
find a unit-length vector, x, which is orthogonal
to each.
- Show that x must satisfy c1 ˘ x = c2 ˘ x = c3 ˘ x = 0.
- What additional equation must x satisfy?
- Find x.
-
Find two unit vectors, a, and b, which
are each orthogonal to the vector, m = 1 ¸Ö3 ( 1, 1, 1 ) ˘.
-
The general linear model, written in matrix notation, is given by
where
y is an n ×1 observation vector,
X is an n ×p design matrix,
b is an p ×1 vector of unknown parameters, and
e is an n ×1 random vector of residuals.
For regression models, X is typically a unit column vector
followed by columns of predictor variables.
For ANOVA models, X is typically a unit vector followed
by columns of indicator (0/1) variables.
- Consider a two-way 2 ×3 ANOVA design with n = 1 observation
per cell (Elswick etal, 1991).
If the model (without interaction) is given by
|
yij = m+ ai + bj + eij, i = 1:2; j = 1:3 |
| (4) |
and the vector of parameters is
b˘ = ( m, a1, a2, b1, b2, b3 ) ,
find the design matrix X so that the elements in y
(a 6 by 1 vector) can be expressed in the form of Eqn. (3).
- By considering linear dependencies among the columns of X,
determine the rank of X. Hazard a guess about the relation
between rank and degrees of freedom.
- Find the row echelon form X* of X
(Try the ECHELON function in APL or SAS
IML).
Does this confirm your observation of the rank of X?
- The product X* b
shows the linear combinations of the elements of b
which can be estimated from the data.
Find X* b and interpret the result.
IV. Transformations, projections & quadratic forms
-
Let x = ( x1 , x2 ) ˘ be a 2-dimensional
vector and consider a rotation in which the vector is rotated
counter-clockwise about the origin through an angle of
q degrees, to a position, x* = ( x1* , x2* ), as shown in Figure 3. In scalar
terms, the rotation can be expressed as
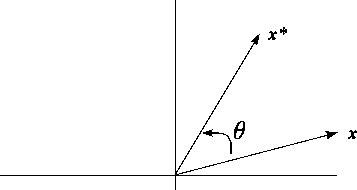 Figure 3:
Rotation of a vector in 2-dimensional
space
Figure 3:
Rotation of a vector in 2-dimensional
space
- Find the matrix T in the matrix expression of the
above equations, x* = T x.
- Show that this matrix T is orthonormal.
-
Let L be a matrix of factor loadings of a set of
tests with respect to one set of coordinate axes. If the
coordinates are rotated, the matrix equation for expressing
the matrix V of loadings with respect to the rotated
axes is V = L T. Suppose there are
four tests and two factors, and L is given by
- Find a matrix T representing a transformation
through a positive angle of 30°.
- Evaluate the product, L T, rounding
to two decimals. Note that some elements in V = L T. are (approximately) zero. The
principle of simple structure in factor rotation
seeks a rotation for which many elements of the rotated
matrix become zero.
-
The rotation procedure of factor analysis can be expressed as a
set of linear transformations, i.e., as a matrix product. Let
V = L T represent such a linear
transformation. The matrix L is a factor matrix
satisfying R = L L˘, where
R is the correlation matrix V is the transformed
factor matrix, and T is a matrix of coefficients which
specifies the rotation.
- Find a condition on the matrix T such that the
transformed factor matrix, V will also
satisfy the factor equation.
- Show that the particular matrix T of problem
1 satisfies this condition, within rounding error.
-
Consider a simple two-dimensional example in which three tests
have these loadings on two underlying factors:
Factor1 Factor2
Test 1 0.50 0.30
Test 2 0.30 0.20
Test 3 -0.40 0.70
Each test can be represented as a point in the plane of
Factor1 (x-axis) and Factor2 (y-axis). Plot these test
points, and find their transformed coordinates when the
coordinate axes are rotated through a positive angle of
37°. Use sin37° = 0.60, cos 37° = 0.80.
-
Let x = ( x1 , x2 ) ˘, and
|
A = |
é
ę
ë
|
|
|
ů
ú
ű
|
, B = |
é
ę
ë
|
|
|
ů
ú
ű
|
|
|
Expand the
following quadratic forms:
- x ˘ A x
- x ˘ B x
- Describe in words the difference between the expansions
in (a) and (b).
-
Describe (or plot) the set of points with coordinates ( x, y )
that satisfy the matrix equations:
| Hint: Multiply out, then repeat: {substitute a
trial value for x and solve for y} |
.
-
|
|
ć
č
|
|
ö
ř
|
|
é
ę
ë
|
|
ů
ú
ű
|
|
ć
ç
č
|
|
ö
÷
ř
|
= 60 |
|
-
|
(x , y) |
é
ę
ë
|
|
ů
ú
ű
|
|
ć
ç
č
|
|
ö
÷
ř
|
= 60 |
|
-
Evaluate the quadratic forms, u ˘ A u , where u = ( x, y, 1 ) ˘ and
where the matrix A is:
|
(a) |
é
ę
ę
ę
ë
|
|
ů
ú
ú
ú
ű
|
(b) |
é
ę
ę
ę
ë
|
|
ů
ú
ú
ú
ű
|
(c) |
é
ę
ę
ę
ë
|
|
ů
ú
ú
ú
ű
|
(d) |
é
ę
ę
ę
ë
|
|
ů
ú
ú
ú
ű
|
|
|
What functions would be obtained by setting each of these
quadratic forms equal to 0?
-
The next few problems demonstrate how some of the common
expressions for sums of squares can be represented by
quadratic forms. Suppose n observations are represented
by a vector x = ( x1 , x2 , ..., xn )
and the sample variance is based on the sum of squared
deviations,
|
SS = |
n
ĺ
i = 1
|
( xi - |
_
x
|
)2 = |
n
ĺ
i = 1
|
xi2 - n |
_
x
|
2
|
|
|
Show that
- [`x] = ( 1 / n ) x ˘ j.
- Sxi2 = x ˘ x.
- n [`x]2 = ( 1 / n ) x ˘ J x = ( 1 / n ) x ˘j j ˘ x, where J is the n × n matrix with all elements equal to 1.
- Hence, show that SS can be expressed by the
quadratic form,
- Write out explicitly the matrix ( I - J / n ) for n = 3. [Source: Searle, 1966]
-
ANOVA and regression tests are based on breaking up sums of
squares into independent, additive portions attributable to
various sources of variance. This problem demonstrates some
of the properties of the quadratic forms associated with these
sums of squares.
Consider the well-known identity for a set of test scores,
yi , i = 1, ..., n:
|
|
n
ĺ
i
|
yi2 = n |
_
y
|
2
|
+ |
n
ĺ
i
|
( yi - |
_
y
|
)2 |
| (5) |
In the previous problem, it was shown that the sum of squared
deviations term could be written as a quadratic form,
|
y ˘ ( I - J / n ) y = y ˘ A2 y (say) |
|
- Show that the above identity (3) can be written as
|
y ˘ A0 y = y ˘ A1 y + y ˘ A2 y |
|
where A0 , A1 , A2 are n ×n symmetric. Find A0 and A1 .
- Show that the following properties hold:
- Show that:
Matrices such as A1 and A2 with these
properties are called idempotent projection
matrices. Every sum of squares formula such as (3) in
ANOVA and regression can be represented as a sum of
quadratic forms with idempotent projection matrices.
- Evaluate the expression,
|
|
y ˘ A1 y / 1
y ˘ A2 y / n - 1
|
|
|
for y = ( 2 , 3 , 3 , 3 , 5 , 8 )˘.
Interpret this expression and state what
statistical test it is used in.
-
In psychological experiments, response classes are often
defined arbitrarily. As a result, an experimenter may wish to
combine response classes when he analyzes data. In formal
models it is useful to have a representation of this procedure
of combining response classes.
Bush, Mosteller & Thompson (1954) use a projection
matrix to combine responses. An example is the matrix,
This matrix is used as follows: Let there be three response
classes initially, with probabilities, r1 , r2 ,
and r3, in a column vector, r.
- Postmultiply P by r, and describe
verbally the result.
- Show that the matrix P satisfies P2 = P.
-
Guttman (1944) discusses a method of factoring a correlation
matrix, based on the equation,
where f is one column of a factor matrix, F;
R is the correlation matrix; and x is a
column vector containing arbitrarily selected coefficients.
Once a single factor has been found using this method, the
same formula can be applied to the residual correlation
matrix, R1 = R - f f ˘, to
find a second factor, and so forth. A factor matrix F
which is build up in this way will always satisfy the basic
equation of factor analysis, F F ˘ = R.
Suppose that the matrix of intercorrelations on four tests is
The elements on the main diagonal of R are not 1.0 as
would be ordinarily expected, but are values called
communalities. representing the variance of each test which
is shared with the other tests.
- Apply Guttman's formula (4) to the matrix R to
find a single column f of the factor matrix.
Assume x to be the vector x = (1, 1, 1, 1 ) ˘
- Show that in this case, f f ˘ = R, or equivalently, R1 = R - f f ˘ = 0. In other words, the only
one factor can account for all the correlations in
R.
[Congradualtions! You've just discovered the basis for factor
analysis.]
-
Resolve the column vector x = ( x1 , x2 , x3 ) ˘ into two components, xa and xb , such that
- x = xa + xb
- xa is parallel to the vector ( 1 , 1 , 1 ) / Ö3
- xb is perpendicular (orthogonal) to ( 1 , 1 , 1 ) / Ö3
[And now, the Gram-Schmidt method for transforming correlated
variables into orthongonal ones!]
-
Arbuckle and Friendly (1977) consider the problem of
transforming a vector of factor loadings, x to a
vector y so that y is as smooth as
possible in the sense that the sum of squares of successive
differences, ĺi = 1n - 1 ( yi - yi + 1 )2 is as small as possible.
- Find an (n-1) ×n matrix P such that
|
P y = |
é
ę
ę
ę
ę
ë
|
|
|
ů
ú
ú
ú
ú
ű
|
= d (say) |
|
- Show that the sum of squares of successive differences
referred to above is given by d ˘ d .
- If y is obtained as a linear combination of
x, by y = T x,
find an expression not using parentheses to express the
sum of squared successive differences in terms of
T, x, and P.
V. Determinants, inverse, and rank
-
Find the inverse of
-
- Verify that the inverse of
- What is the inverse of
Can you determine
what the inverse of any diagonal matrix is?
-
If
show that | A | = a11 a22 - a21 a12 = a11 ( a22 - a21 a11-1 a12 ).
This last expression has an important analog for partitioned
matrices.
-
A frequent question in the testing field is whether to add
another test to a battery of n tests to attempt to increase the
prediction of an external criterion. Horst (1951) proposes a
time-saving method of answering this question. He derives a
formula for the validity of an additional test, k, that
would be required to increase the validity of the battery by an
amount a.
Let R be the (n+1) ×(n+1) matrix of
intercorrelations, partitioned with test k as the last row
and column,
where R* is the n ×n matrix of
correlations of all tests except test k, and rk is the column vector of correlations of test k with
each other test.
To develop his formula, Horst needed to find the inverse of
R, that is a matrix S, such that R S = I, the identity matrix. Thus, S = R-1.
- Partition the matrix S conformably with R,
as
and
write out the equation R S = I in
terms of partitioned matrices.
- Write out the four sub-matrix equations implied by the
equation in part (a).
- Find S = R-1 by solving for S*, u, and d.
-
If a matrix is upper (lower) triangular, then its inverse is
also upper (lower) triangular. Show that this is true for the
matrix S below by finding its inverse.
Hint: Let
and write out the 9 scalar equations implied
by S-1 S = I.
-
In a ratio scaling experiment four stimuli are presented in all
possible pairs to the subject. For each pair, the subject is
required to give a number representing the relative
``strength'' of the first stimulus compared to the second.
For example, he/she may be asked to judge the relative
brightness of two lights, or which of two tones is higher in
pitch.
One hypothesis for this type of judgment is that the subject
has internal subjective intensity values for each stimulus,
and to make a judgment, ``computes'' and reports the ratio of
the two values for a pair.
Let the matrix R = { rij } contain the judgments of
each pair, for stimulus i relative to stimulus j, and
let s = ( s1 , ..., sn ) ˘ be a vector
of the subject's internal scale values for these stimuli.
- Express the hypothesis, rij = si ¸sj in
matrix terms.
- What does this hypothesis imply about the rank of
R if the model holds?
- What does this imply about the latent roots of R ˘ R?
-
In the randomized block design, each of n subjects is given
each of a series of p experimental treatments, resulting
in a score, yij = score of subject i under treatment
j. With one observation per cell, the standard analysis
of variance model (without interaction) is,
- Write Y (n ×p) = yij and express
Y in terms of ai, and bj as
a product of two matrices.
- Tukey's ``one degree of freedom for non-additivity''
adds an additional term to this model, giving:
|
yij = ai + bj + g ai bj ( + eij ) |
|
where g is one additional parameter to be estimated.
Write a matrix product expression for
Y in this model. [You may not simply multiply Y by
the identity matrix. Use no + signs in the elements in
the factors in your product.]
- What is the rank of Y if the model of part (a)
holds?
- What is the rank of Y if the model of part (b)
holds?
-
Suppose an animal running a maze is scored under 3 experimental
conditions for (a) number of wrong turns made, (b) number of
pauses, and (c) time to reach the goal. Some data is given
below, with scores expressed as deviations from the column
means.
Errors Pauses Time
Cond. 1 2 0 4
Cond. 2 1 6 10
Cond. 3 -3 -6 -14
- Determine the rank of this matrix.
- If time and errors have been measured, does the pause
measure contribute any additional information?
- If e is the (column vector) number of errors,
p is the number of pauses, and t
the time taken, can you find a constant a to make the
following equation true for these data?
VI. Simultaneous equations
-
On a sheet of graph paper draw lines representing each of the
three linear equations,
- Show that this system of equations has no solution and
interpret this fact with reference to your geometrical
interpretation.
- Suppose we adopt the following procedure for ``solving''
the system. Take the equations and solve them in
pairs- (1) and (2), (1) and (3), (2) and (3). This
will give values, say ( x1 , y1 ), ( x2 , y2 ), and ( x3 , y3 ) which may not
agree. ``Solve'' the equations in this way and locate
the solution points on your graph.
- Now, suppose we adopt as the final solution to this
system the average value,
|
( |
_
x
|
, |
_
y
|
) = |
ć
ç
č
|
|
(x1 + x2 + x3 )
3
|
, |
(y1 + y2 + y3 )
3
|
ö
÷
ř
|
|
|
Locate this point on your graph and interpret
geometrically.
-
Show that the system of equations,
is underdetermined. That is, there is no unique pair ( x , y ) which satisfy both equations.
- Draw these two equations as lines on a graph and explain
why there is no unique solution.
- If the second equation is changed to 2 x + 2 y = 3, explain why these two equations become
inconsistent.
VII. Latent roots and vectors
Multiplication of a vector v by a square matrix A
can be regarded as a mapping or transformation of v into
some other vector, v* in the vector space,
A latent vector, or eigenvector of the
matrix A is a special vector whose direction is unchanged by
that transformation. That is, if v is a non-zero vector
such that
then v is an eigenvector or latent vector of A, and
k, the constant of proportionality, is the eigenvalue or latent
root corresponding to v.
-
In Householder's method for determining eigenvalues of a real
symmetric matrix, A, the matrix is subjected to a series
of orthogonal transformations of the form
|
P = I - 2 w w ˘ where w ˘ w = 1 |
|
- Show that P is orthonormal and symmetric.
- If the latent roots of A are l1 , l2 , ..., ln, what are the latent
roots of P A P ?
- If the latent vectors of A are v1 , v2 , ..., vn, what are the
latent vectors of P A P ?
-
The eigenvalues and eigenvectors of any square, symmetric
matrix A ( n ×n ) can (in principle) be found
by (1) finding the n values of l which satisfy
| A - lI | = 0; (2) solving A v = lv for v using each
value of l determined by step (1). Using this
method, find the eigenvalues and eigenvectors of the following
matrices:
|
(a) |
é
ę
ë
|
|
ů
ú
ű
|
(b) |
é
ę
ë
|
|
ů
ú
ű
|
|
|
-
Show that the eigenvalues of the matrix
are ±1.
-
In the Markov model for serial learning outlined in Problem
27 verify that the eigenvalues of the transition
matrix, T are
| Hint: Solve the characteristic equation | T - lI | = 0. |
-
A magic square is a matrix in which the elements of each
row, column and the two main diagonals add up to the same
number, this number being called the magic number For
the magic square, A, below, show that one latent root of
this magic square is its magic number. (This is true for all
magic squares).
References
- [1]
- Arbuckle, J. & Friendly, M.L. (1977).
On rotating to smooth functions. Psychometrika,
42, 127-140.
- [2]
- Bush, R.R., Mosteller, F. & Thompson, G.L. (1954).
A formal structure for multiple choice situations. In
Thrall, Coombs & Davis (Eds.) Decision processes.
NY: Wiley.
- [3]
- Cliff, N. (1959).
Adverbs multiply adjectives. Psychological Review,
66, 27-44.
- []
- Elswick, R. K., Jr., Gennings, C., Chinchilli, V. M.,
and Dawson, K. S. (1991).
A simple approach for finding estimable functions in
linear models. The American Statistician, 45, 51-53.
- [4]
- Guttman, L. (1944).
General theory and methods of matric factoring.
Psychometrika, 9, 1-16.
- [5]
- Horst, P. (1951).
The relation between the validity of a single test and its
contribution to the predictive efficiency of a test battery.
Psychometrika, 16, 57-66.
- [6]
- Judd, D.B. (1951).
Basic correlates of the visual stimulus. In S. S. Stevens
(Ed.) Handbook of experimental psychology New York:
Wiley.
- [7]
- Kendall, D. G. (1969).
Some problems and methods in statistical archaeology.
World Archaeology, 1, 61-.
- [8]
- Kendall, M.G. (1962).
Rank correlation methods London: Griffin.
- [9]
- Murdock, B. B. Jr. (1976).
Item and order information in short-term serial memory.
Journal of Experimental Psychology: General, 105,
191-216.
- [10]
- Searle, S.R. (1966).
Matrix algebra for the social sciences New York: Wiley.
- [11]
- Van de Geer, J.P. (1971).
Introduction to multivariate analysis for the social
sciences San Francisco: W. H. Freeman.
- [12]
- Williams, G. (198?).
Mathematics in archaeology. Mathematics Teacher,
?, 56-58.
File translated from
TEX
by
TTHgold,
version 2.78.
On 19 Oct 2001, 12:37.